The Office Part I: Employee Attrition
By Katie Press in Projects Enron
June 22, 2021
Background
This post is partially inspired by one of my favorite blogs ever, Ask a Manager. I am obsessed with this content - partly because Alison (the writer) is super smart and gives good advice, partly for the pure entertainment value. I’ll be linking to some great posts along the way, but in the meantime here is a list of Alison’s favorite posts ever.
In the past whenever I needed to create a predictive model, I was always frustrated because I wanted to know what the best model would be given all possible combinations of variables. But you wouldn’t want to test all combinations of all variables, because some of them are too similar and would over-inflate the model. For example, I wouldn’t use a variable like “age at event x” and another variable “age over 18 at event x” in one model.
A few weeks ago I was taking an online Python course and the course was covering truth tables, which look like this:
In order for the third column (A or B) to be true, either A or B, or both A and B need to be true.
I realized I needed to do was figure out how to recreate a truth table where each column represents a group of potential variables for the model. This post is based on a real project, but I needed some publicly-available data to demonstrate with. I know there is a heart disease that is often used for prediction, but that’s kind of…boring. Also there weren’t that many variables.
Then I came across this HR employee attrition dataset on Kaggle and thought that might be more interesting, given some of the crazy stories I’ve read on Ask a Manager over the years that often resulted in people leaving,, sometimes in rather spectacular fashion.
In this post I’ll cover a little bit of data import and cleaning, visualization, and finally how to create a bunch of models at once. I’ve loaded the following packages:
- tidyverse
- lubridate
- janitor
- knitr
- ggplot2
- readxl
- ggridges
- broom
- glue
Data Import
I downloaded the csv files from Kaggle and created an R Project in the same folder.
- Get list of csv files
- Use purrr::map to read csv into a list of tibbles
- Name the tibbles in the list (this is why I put “full.names = TRUE”)
- Map over the tibbles with janitor’s clean_names function to make the column names all lower case separated by underscores.
temp.list <- list.files(full.names = TRUE, pattern = "*.csv", path = "~/Desktop/Rproj/employee/")
data_list <- map(temp.list, read_csv)
names(data_list) <- word(temp.list, -2, sep = "/|\\.csv")
data_list <- data_list %>%
map( ~.x %>% clean_names)
I have a list of five tibbles, two of which are timestamp datasets and not in tidy format yet.
summary(data_list)
## Length Class Mode
## employee_survey_data 4 spec_tbl_df list
## general_data 24 spec_tbl_df list
## in_time 262 spec_tbl_df list
## manager_survey_data 3 spec_tbl_df list
## out_time 262 spec_tbl_df list
General Data
We have a general dataset, a manager survey, and an employee survey. These three tables can be joined on employee ID.
Side note: If you are a manager, try not to force your employees to complete a daily mental health survey, it’s not a great look and they’ll probably all quit.
data <- data_list$general_data %>%
left_join(data_list$employee_survey_data) %>%
left_join(data_list$manager_survey_data) %>%
select(employee_id, everything())
Time Data
This is what the time data looks like currently. Notice each column is a date, except for the first one which corresponds to the employee ID. This is exactly what tidyr is for.
Using pivot_longer, I can preserve the employee ID in one column, put the date in another column, and the timestamp in a third column. I usually use lubridate to format dates, in this case I also had to get rid of the “x” at the beginning of the character because otherwise it would be NA. I’m also going to add the timestamps for clocking out.
time_data <- data_list$in_time %>%
pivot_longer(!x1, names_to = "date", values_to = "time_in") %>%
mutate(date = ymd(str_remove_all(date, "x"))) %>%
left_join(
data_list$out_time %>%
pivot_longer(!x1, names_to = "date", values_to = "time_out") %>%
mutate(date = ymd(str_remove_all(date, "x")))
) %>%
rename("employee_id" = x1)
Create some additional variables for aggregation later. This would be especially useful for any nosy coworkers who might want to track your hours.
- Number of hours worked each day
- Week column
time_data <- time_data %>%
mutate(hours = round(time_length(time_in %--% time_out, "hour"), 2)) %>%
mutate(hours = replace_na(hours, 0)) %>%
mutate(week = week(date))
Much better
Data Cleaning
Using the data dictionary Excel file provided from Kaggle, I’m recoding some of the numeric variables as factors for better visualization in charts. Also create a numeric variable for attrition (to be used later in modeling).
data <- data %>%
mutate(education_2 = factor(
education,
labels = c("Below College", "College", "Bachelors", "Masters", "Doctoral"),
ordered = TRUE
)) %>%
mutate(across(
one_of(
"environment_satisfaction",
"job_involvement",
"job_satisfaction"
),
list("2" = ~ factor(
., labels = c("Low", "Medium", "High", "Very High"),
ordered = TRUE
))
)) %>%
mutate(performance_rating_2 = factor(performance_rating,
labels = c("Excellent", "Outstanding"),
ordered = TRUE)) %>%
mutate(work_life_balance_2 = factor(work_life_balance,
labels = c("Bad", "Good", "Better", "Best"),
ordered = TRUE)) %>%
mutate(business_travel = str_replace_all(business_travel, "_", " ")) %>%
mutate(attrition_2 = ifelse(attrition == "Yes", 1, 0))
Aggregate the timestamp data down to average hours worked per week and add to the dataset.
data <- time_data %>%
group_by(employee_id, week) %>%
summarise(week_hours = sum(hours)) %>%
group_by(employee_id) %>%
summarise(avg_weekly_hours = round(mean(week_hours, na.rm=TRUE))) %>%
right_join(data)
Data Viz
Checking out some of the numeric variables, I can plot multiple histograms using ggplot and facet_wrap. And here are some fun Ask a Manager posts to go along with them:
- A reader’s direct report is obsessed with her age
- What to do when you’re working crazy hours and your boss reprimands you for coming in late
- If you’re an entry level employee, maybe think twice before giving your manager “constructive” feedback
data %>%
select("Age" = age,
"Average Weekly Hours" = avg_weekly_hours,
"Job Level" = job_level,
"Number of Companies Worked" = num_companies_worked,
"Total Working Years" = total_working_years,
"Training Times Last Year" = training_times_last_year,
"Years at Company" = years_at_company,
"Years Since Last Promotion" = years_since_last_promotion,
"Years with Current Manager" = years_with_curr_manager) %>%
gather(item, number) %>%
ggplot(aes(number, color = item, fill = item))+
geom_histogram(binwidth = 1)+
facet_wrap(~item, scales = "free")+
my_theme +
theme(legend.position = "none",
axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.title.x = element_blank(),
axis.ticks.y = element_blank())
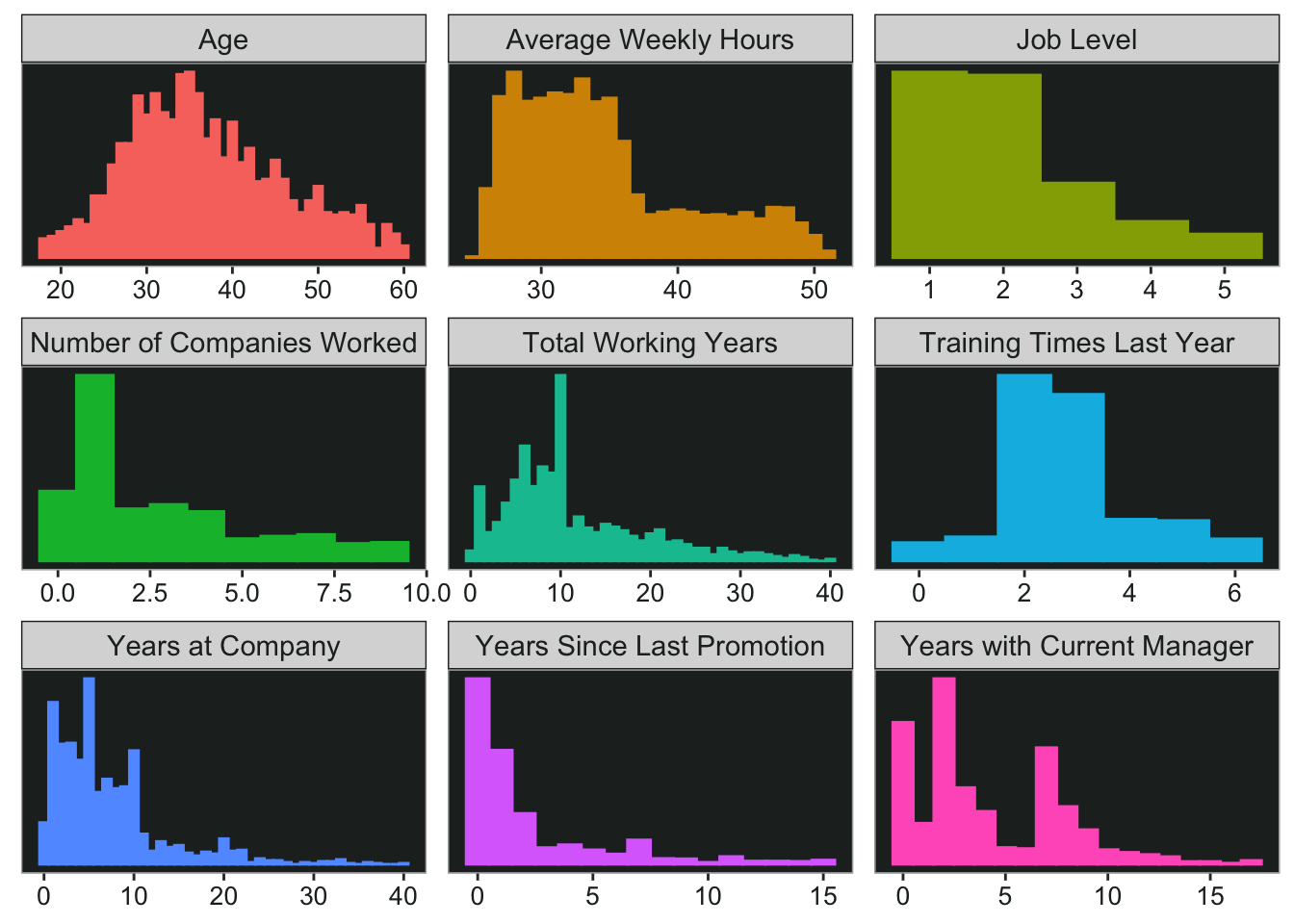
Bar Charts
For the categorical variables it’s not quite as easy to plot multiple charts at once. But I can start by nesting the data. This gives me a list of dataframes - one for every item I want to plot.
plot_data <- data %>%
select("Gender" = gender,
"Marital Status" = marital_status,
"Business Travel" = business_travel,
"Work Life Balance" = work_life_balance_2,
"Education" = education_2,
"Education Field" = education_field,
"Department" = department,
"Job Role" = job_role,
"Environment Satisfaction" = environment_satisfaction_2,
"Job Involvement" = job_involvement_2,
"Job Satisfaction" = job_satisfaction_2,
"Performance Rating" = performance_rating_2
) %>%
gather(item, thing) %>%
count(item, thing) %>%
group_by(item) %>%
mutate(pct = n/sum(n)) %>%
group_nest(data = item)
Now I can use map to iterate over the dataframes with my ggplot code. I’m actually using map2 here so that I can use the “item” column as titles for the charts (pasted in using glue). Now I have the plots in a new column and I can print them out.
plot_data <- plot_data %>%
mutate(
plot = map2(
data,
item,
~ ggplot(data = .x, aes(
x = pct, y = thing, fill = thing
)) +
ggtitle(glue("{.y}")) +
geom_col() +
scale_x_continuous(labels = scales::percent_format(accuracy = 1)) +
my_theme +
theme(axis.title.y = element_blank(),
axis.title.x = element_blank(),
plot.title = element_text(size = 12))
)
)
## # A tibble: 6 × 3
## item data plot
## <chr> <list<tibble[,3]>> <list>
## 1 Business Travel [3 × 3] <gg>
## 2 Department [3 × 3] <gg>
## 3 Education [5 × 3] <gg>
## 4 Education Field [6 × 3] <gg>
## 5 Environment Satisfaction [5 × 3] <gg>
## 6 Gender [2 × 3] <gg>
I’m using ggarrange so that I can lay them out in a grid and make them the same size using horizontal + vertical alignment. Thankfully ggarrange already has a plotlist argument, so I don’t have to write out every plot in the list separately.
Note: If you don’t want NAs in your charts, you can replace them using fct_explicit_na from the forcats package.
Speaking of variables, here are some more related posts from Ask a Manager:
- If your company has a leadership training program for women, try not to be a jerk about it
- Speaking of marital status, what happens when your dad is dating your boss and they want you to go to couples therapy with them?
ggpubr::ggarrange(
plotlist = plot_data$plot,
nrow = 4,
ncol = 3,
align = 'hv'
)
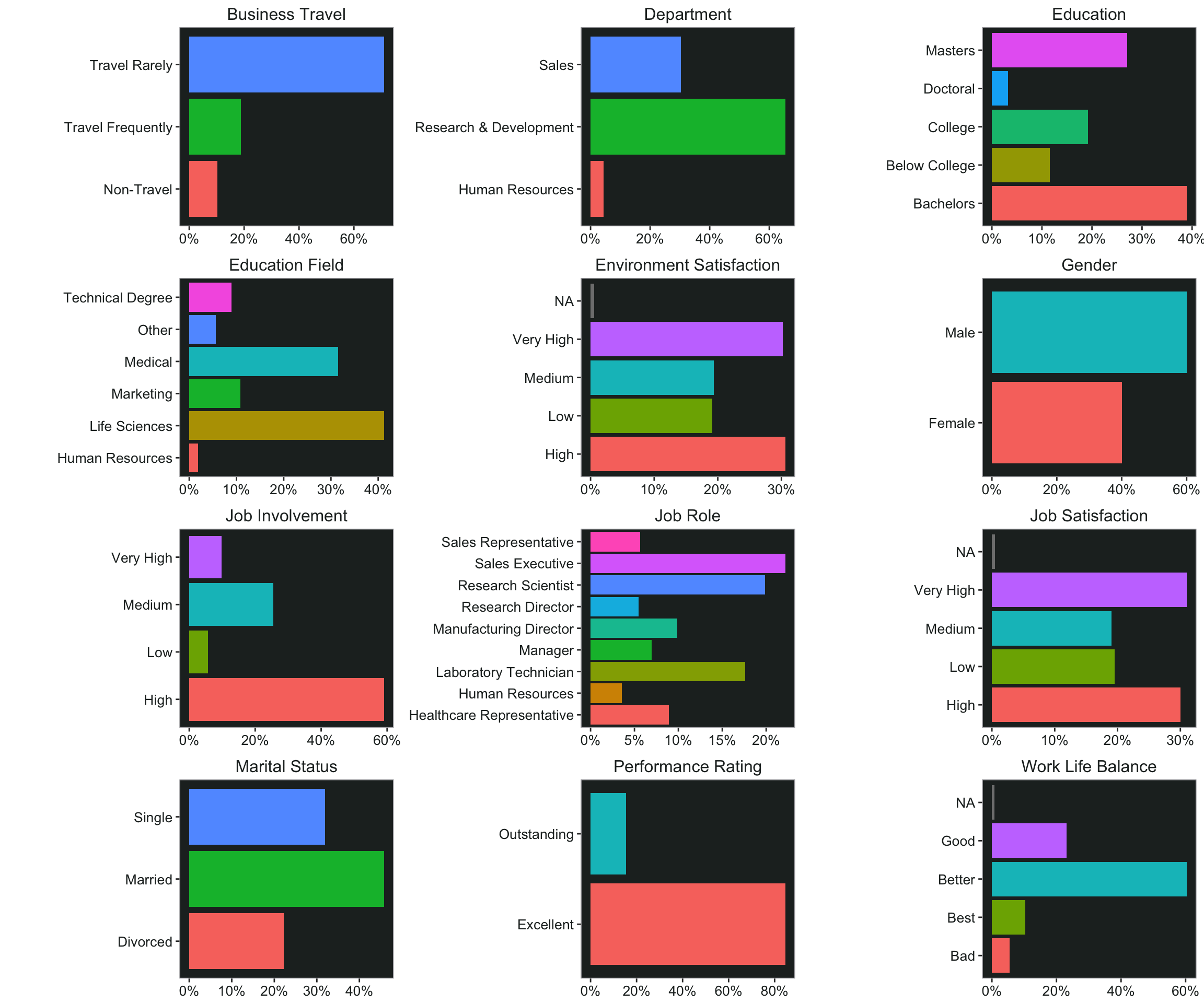
Ridgeline Charts
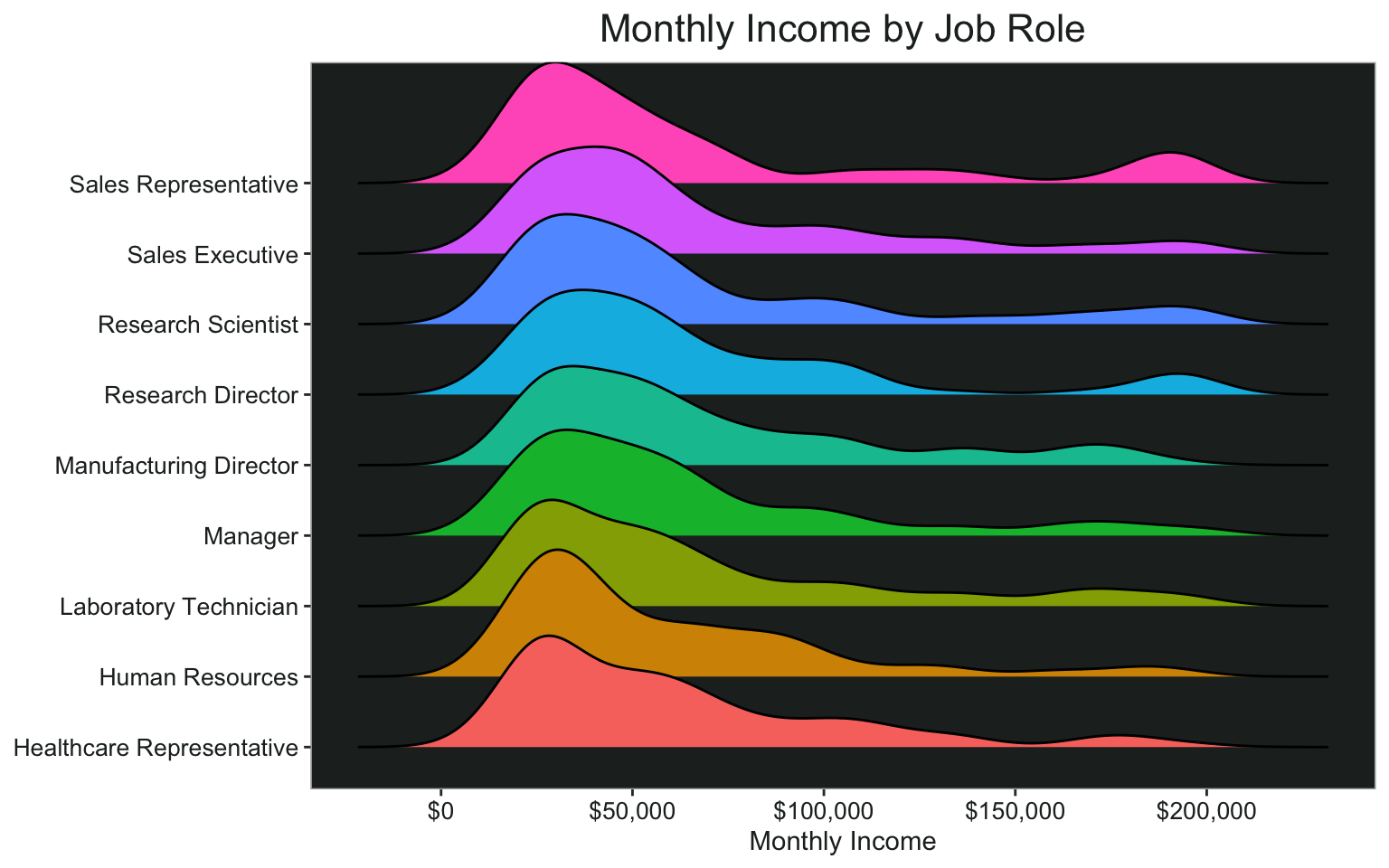
I would like to visualize how some of the variables interact with each other. Ridgeline charts can be a good way to do that, and they look pretty cool.
ggplot(data, aes(x = monthly_income, y= job_role, fill = job_role))+
geom_density_ridges()+
scale_x_continuous(name = "Monthly Income", labels = scales::dollar)+
ggtitle("Monthly Income by Job Role")+
my_theme+
theme(axis.title.y = element_blank())
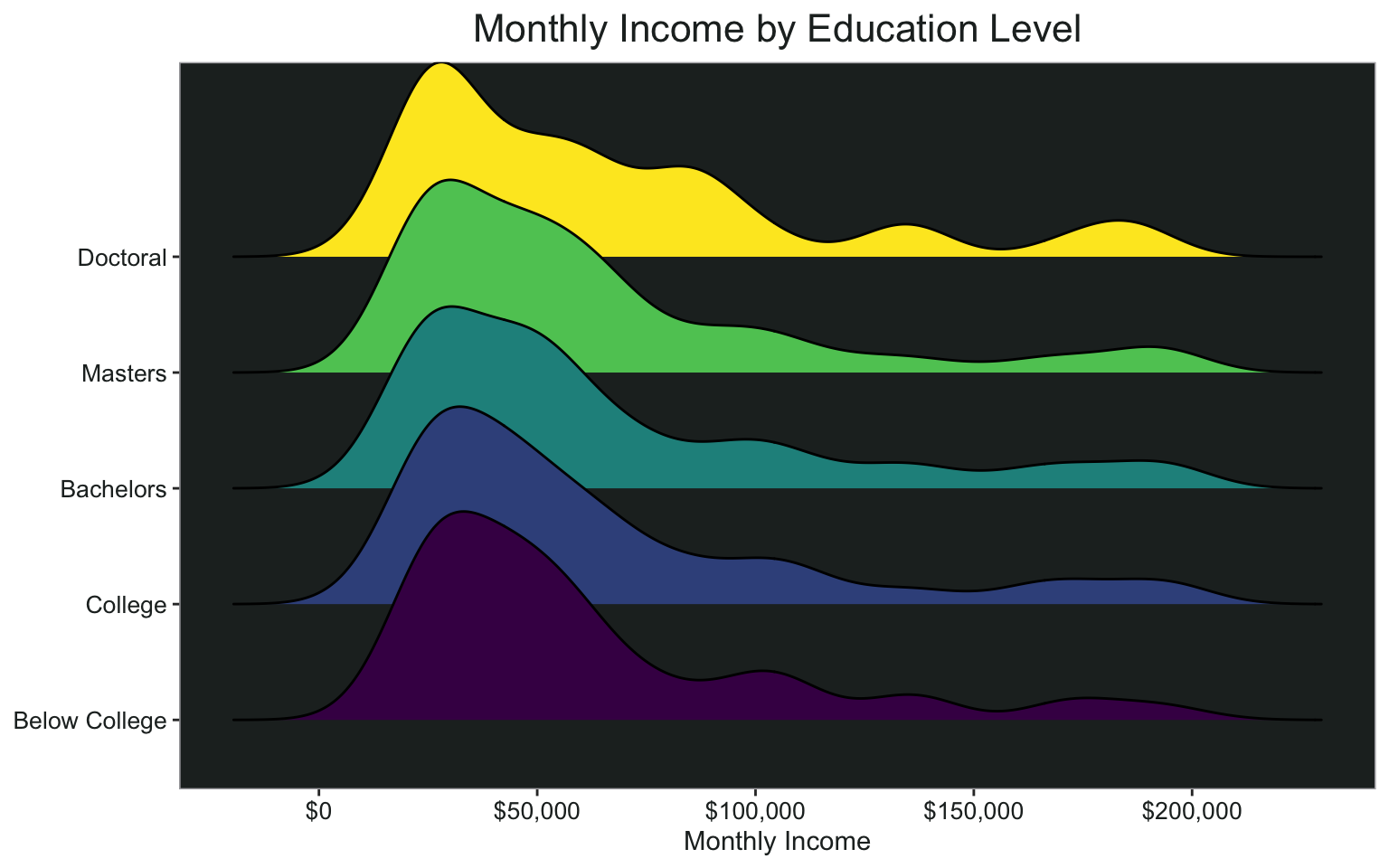
By level of education:
ggplot(data, aes(x = monthly_income, y= education_2, fill = education_2))+
geom_density_ridges()+
scale_x_continuous(name = "Monthly Income", labels = scales::dollar)+
ggtitle("Monthly Income by Education Level")+
my_theme+
theme(axis.title.y = element_blank())
Creating the Models
Now that I’ve cleaned up and explored the data a little bit, it’s time to start the modeling process.
Creating Variable Groups
To create my “truth table” for all possible combinations of variables to model, I need to group my variables into categories. Some of these probably could be grouped in different ways, but this is just for demonstration purposes so it doesn’t have to be perfect. I’m wrapping all the groups in the crossing() function from tidyr, which will expand these lists to all possible combinations of the different variable groups.
cross_df <- crossing(
age = c("age", "total_working_years", "num_companies_worked"),
demos = c("gender", "marital_status"),
company_time = c(
"years_at_company",
"years_since_last_promotion",
"years_with_curr_manager"
),
work_life_balance = c(
"distance_from_home",
"business_travel",
"work_life_balance",
"avg_weekly_hours"
),
level = c(
"education",
"job_level",
"monthly_income",
"stock_option_level"
),
work_type = c("education_field", "department", "job_role"),
performance = c(
"performance_rating",
"training_times_last_year",
"percent_salary_hike"
),
satisfaction = c("environment_satisfaction", "job_satisfaction")
)
This is what the resulting tibble looks like. There are 5,184 different possible model combinations.
Creating Formulas
Now I have variables I need for the model but they’re all in different columns. I need to make it look more like the formula I’m going to use. To do that, I can use unite (also from tidyr). I’ll combine columns 1 through 8 into a new column called “formula”, separated by the plus sign because that’s the syntax the model will need as an input.
Then I paste the outcome variable (attrition_2) in front of the formula, just like it would be in a glm model. Add a model name to help keep track of everything later on.
formula_df <- cross_df %>%
unite(formula, c(1:8), sep = "+") %>%
select(formula) %>%
mutate(formula = paste0("attrition_2 ~ ", formula)) %>%
mutate(model_name = row_number())
This is what the formula looks like
First I will create a function that I can map over my dataset of formulas. This is just a regular binomial logistic regression model.
mod_fun <- function(x) {glm(formula = as.formula(x), family = binomial("logit"), data = data)}
Mapping the Models
Now map over the models. WARNING - this will take a minute. It’s a bit faster if you don’t ask for the odds ratios (exponentiated coefficients). If you have a very large dataset, you’re going to want to test this on just a couple of your formulas to make sure you’ve got everything set up right. If you have a really, really large dataset, you can always run it in batches as well. What this does is:
- Map over each cell in the formula column using the formula I created
- Using the broom package, create a new tidied column for the model summary and model fit
- Unnest the model summary and fit info into a tidied dataframe
model_df <- formula_df %>%
mutate(models = map(formula, mod_fun),
model_summary = models %>% map(~tidy(., exponentiate = TRUE)),
model_fit = models %>% map(glance)) %>%
select(model_name, model_summary, model_fit) %>%
unnest(c(model_summary, model_fit)) %>%
mutate_if(is.numeric, ~ round(., 3))
Filtering Model Data
Now I have a tidy dataset of all the models of all possible combinations of variables in my pre-defined groups. I can filter based on whatever criteria is most important.
Lowest AIC
For example, here is the model with the lowest AIC:
All Significant Variables
Or I could look for models where every variable is statistically significant, or filter to ensure that the model contains one variable I’m particularly interested in.
Significance of Terms Across Models
I could look at how many times a particular term was considered significant across all models. It looks like environment satisfaction, job satisfaction, marital status, age,department, and education field are all near the top of the list. However, stock option level, gender, and a few of the job roles were not significant in many of the models (if at all).
Odds Ratios of Significant Terms Across Models
I can also look at the statistically significant terms to see how their odds ratios differ across the models.
plot2 <- model_df %>%
filter(!str_detect(term, "Intercept"), p.value < .01) %>%
count(term, estimate) %>%
mutate(term = str_to_sentence(str_replace_all(term, "_", " "))) %>%
filter(estimate != 0, !str_detect(term, "income")) %>%
mutate(term = str_replace_all(term, "Marital status", "Marital status: "),
term = str_replace_all(term, "Job role", "Job role: "),
term = str_replace_all(term, "Education field", "Field: "),
term = str_replace_all(term, "Department", "Dept: "),
term = str_replace_all(term, "Business travel", "Travel: "))
ggplot(plot2, aes(x = estimate, y = term, fill = term)) +
geom_density_ridges(scale = 2
) +
theme_ridges() +
scale_x_continuous(name = "Odds Ratio")+
theme(legend.position = "none")+
ggtitle("Likelihood of Attrition", subtitle = "by Significant Terms Across All Models")+
my_theme+
theme(axis.title.y = element_blank(),
axis.title.x = element_text(family = "Arial", hjust = .5))
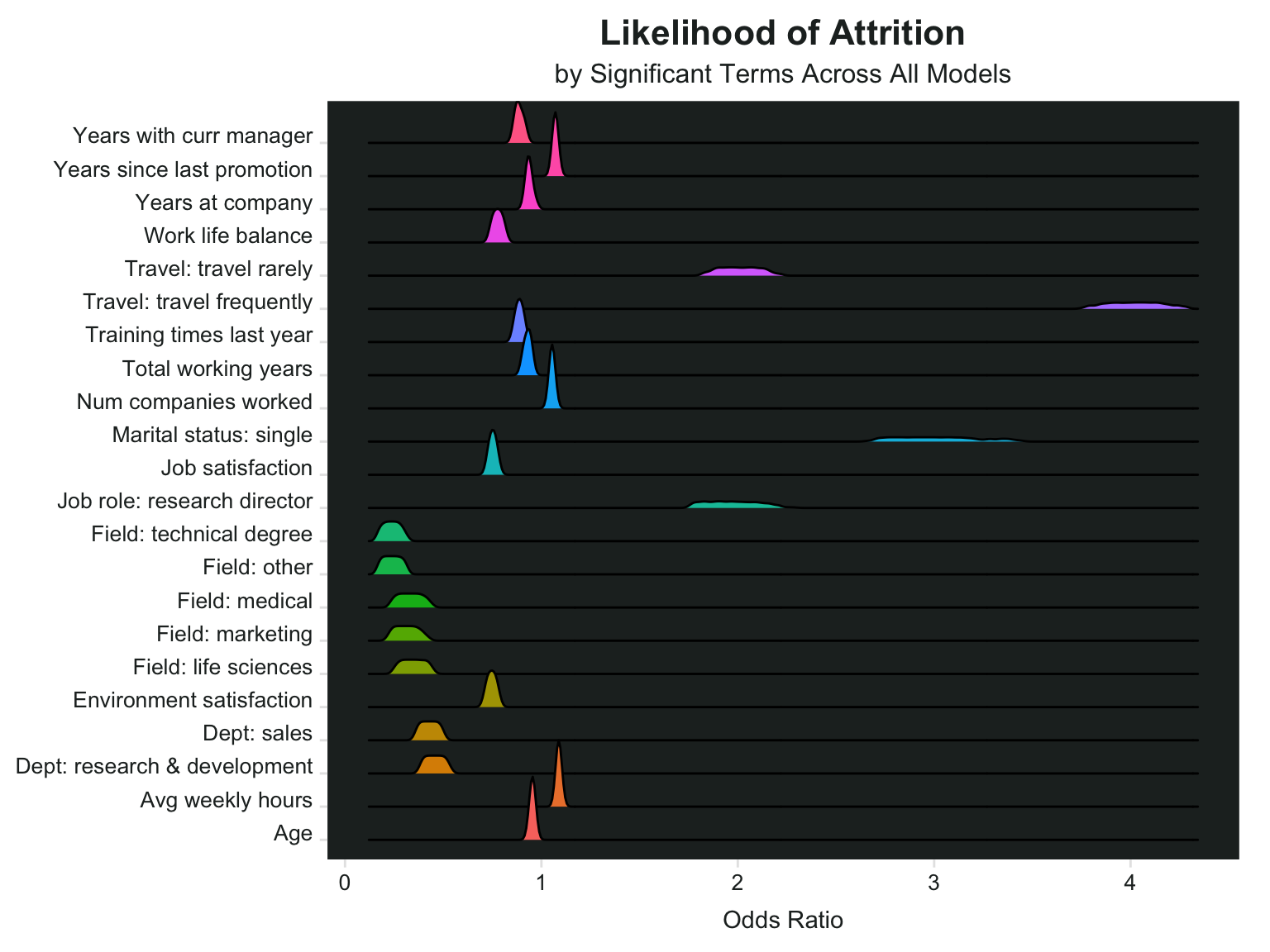
It looks like people who travel frequently have some of the highest odds ratios, which means they are more likely to leave their jobs. People who travel rarely are also likely to leave - in comparison to those who don’t travel at all. Single people and research directors also have high likelihoods of leaving. These four variables also seem to vary the most in terms of the odds ratio across all models. For example the lowest odds ratio for marital status: single was around 2.6 and the highest was around 3.4.
Average weekly hours, number of companies worked for, and years since last promotion all had a slightly higher likelihood of leaving, and their odds ratios were quite similar across all models. The lowest odds ratio for average weekly hours was 1.08, and the highest was 1.096.
Some variables are associated with lower likelihood of leaving, for example age (older) and years at the company, some education fields and job roles.
Selecting a Final Model
I could use the information in the previous chart to filter down and select a final model. For example, I might want to ensure that the travel variable is included, along with marital status. And make sure they are both significant in whatever models I bring up. This set of filtering criteria gives me 648 models to choose from.
Speaking of marital status, there are so many good spouse-related posts.
- A job candidate’s suspicious husband photographs her interviewer
- When you accidentally start dating your new boss’s husband
And speaking of travel, this is one of my favorite posts ever - this poor woman got in trouble for what she was wearing when her boss made her pick him up in the middle of the night. Just… wtf?
temp_models <- model_df %>%
group_by(model_name) %>%
filter(any(str_detect(term, "travel") & p.value < .05), any(str_detect(term, "marital") & p.value < .05))
distinct(temp_models, model_name) %>% nrow()
## [1] 648
That’s still probably too many, so I’ll add a filter for education field as well, since there are several fields that are less likely to leave. Now there are “only” 216 models.
temp_models <- temp_models %>%
group_by(model_name) %>%
filter(any(str_detect(term, "field") & p.value < .05))
distinct(temp_models, model_name) %>% nrow()
## [1] 216
You know what they say, people don’t quit a job they quit a boss. Especially if they have one of the worst bosses of 2020. Let’s also keep the years with current manager and job satisfaction variables. Down to only 36 models.
temp_models <- temp_models %>%
group_by(model_name) %>%
filter(any(str_detect(term, "job_sat") & p.value < .05), any(str_detect(term, "manager") & p.value < .05))
distinct(temp_models, model_name) %>% nrow()
## [1] 36
It looks like model 4998 is the winner with the lowest AIC out of those 36. All of the variables are significant except for job_level, which is probably fine.
temp_models <- temp_models %>%
ungroup() %>%
filter(AIC == min(AIC))
Using the Model
What to do with the information from all these models? Some companies actually use predictive models that spy on their employees’ work computers and monitor their emails and LinkedIn activity to try and figure out who is thinking about leaving. What they do with this information may or may not be good (like a retention bonus), but it’s still creepy either way. I could create a sort of “attrition score” using the variables in this model.
Item Analysis
Create some scores for each item in the model. Here I’ll write a little function to tell me the proportion of staff who left for each variable so I don’t have to copy and paste so much.
tbl_att <- function(df, col){
col <- enquo(col)
df %>%
count(!!col, attrition) %>%
group_by(!!col) %>%
mutate(pct = scales::percent(n/sum(n), accuracy = .1)) %>%
filter(attrition == "Yes")
}
Total Number of Working Years
Looks like people who have worked for 0-1 years total have a high proportion of leavers.
data <- data %>%
mutate(total_working_years_score = ifelse(total_working_years < 2 & !is.na(total_working_years), 2, 0))
Marital Status
Single people have the highest proportion of attrition
data <- data %>%
mutate(marital_status_score = ifelse(marital_status == "Single", 1, 0))
Years with Current Manager
People with new managers (or new-to-them managers) are more likely to leave.
data <- data %>%
mutate(years_manager_score = ifelse(years_with_curr_manager == 0, 1, 0))
Business Travel
People who travel at all are more likely to leave than those who don’t travel, but people who travel frequently have a higher proportion of attrition.
data <- data %>%
mutate(travel_score = ifelse(business_travel == "Travel Frequently", 2,
ifelse(business_travel == "Travel Rarely", 1, 0)))
Job Level
Job level wasn’t significant in the model and I can see why, there’s not much distinction between levels as far as attrition goes. Maybe I’ll just reverse code for job level 5.
data <- data %>%
mutate(job_level_score = ifelse(job_level == 5, -1, 0))
Education Field
Human resources are much more likely to leave than any other education field. This is the variable all the others in the model tested against, so it makes sense why all the other education fields looked like they were less likely to leave. What’s up with HR?
data <- data %>%
mutate(education_field_score = ifelse(education_field == "Human Resources", 2, 0))
Training Times Last Year
It looks like maybe people who had a lot of training had lower attrition.
data <- data %>%
mutate(training_score = ifelse(training_times_last_year < 4, 1, 0))
Job Satisfaction
Job satisfaction - 4 is very high, 1 is low.
data <- data %>%
mutate(job_satisfaction_score = ifelse(is.na(job_satisfaction) | job_satisfaction == 4, 0,
ifelse(between(job_satisfaction, 2,3), 1, 2)))
Attrition Risk Score and Level
Now add them all up to create a score and plot it. There are some people who have an attrition score of 0, by the way, but none of them left.
data <- data %>%
select(employee_id, contains("score")) %>%
mutate(attrition_score = rowSums(.)) %>%
mutate(attrition_score = attrition_score -employee_id) %>%
left_join(data)
p1 <- count(data, attrition_score, attrition) %>%
group_by(attrition_score) %>%
mutate(pct = n/sum(n)) %>%
filter(attrition == "Yes") %>%
ggplot(aes(x = attrition_score, y = pct))+
scale_y_continuous(name = "Percent Attrition", labels = scales::percent)+
scale_x_continuous(name = "Attrition Score", breaks = seq(1,11,1))+
geom_line(color = pal.9[6], size = 1.2)+
my_theme
I can also make a risk level based on the scores.
data <- data %>%
mutate(attrition_level = factor(
ifelse(
between(attrition_score, 0, 3),
"Low",
ifelse(between(attrition_score, 4, 6), "Medium", "High")
),
levels = c("Low", "Medium", "High")
))
p2 <- data %>%
count(attrition_level, attrition) %>%
group_by(attrition_level) %>%
mutate(pct = n/sum(n)) %>%
filter(attrition == "Yes") %>%
ggplot(aes(x = attrition_level, y = pct, fill = attrition_level))+
geom_col()+
geom_text(aes(x = attrition_level, y = pct, label = scales::percent(pct), group = attrition_level),
position = position_stack(vjust = .5), color = "white", size = 5)+
scale_fill_manual(values = c(pal.9[7], pal.9[8], pal.9[9]))+
labs(x = "Attrition Level")+
my_theme+
theme(axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank())
ggpubr::ggarrange(p1, p2, align = 'hv')
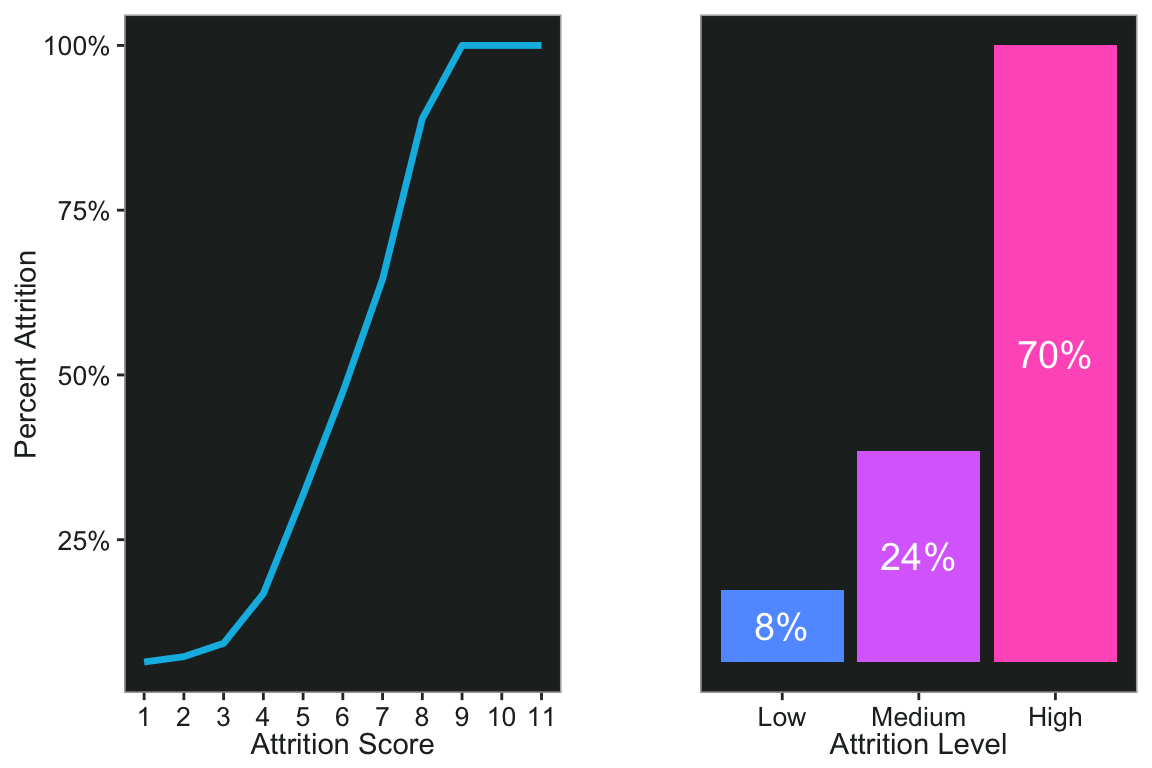
Next time maybe I’ll do some latent profile analysis on this dataset.