I Want to Believe
By Katie Press in Projects XFiles
November 1, 2020
Web Scraping X-Files Scripts
In the last “episode” I created a dataset of X-Files episodes using web scraping. The simple episode descriptions are not going to give me the depth of information I need for a real text analysis, so it’s time to get some more data!
Many of the X-Files episode transcripts are available online, so I found a website I could use to scrape most of the text I need. First, I’m going to create a list of episode links that I can use to download the transcripts. There are 202 transcripts, so I can simply repeat the link 202 times and add the .txt at the end.
links <- rep(paste0("http://scifi.media/wp-content/uploads/t/x/", 1:202, ".txt"))
Now I want to use read_csv to read each link as a new CSV in a list. However, the first time I tried to do this, episode 185 did not import correctly. Upon further investigation, I determined that this was due to a special character in the epiosde name “DÆMONICUS”. Basically, this is an encoding issue. I just tested out a couple different encoding types and pretty easily found one that worked. Note: I tested them on a subset of just episode 184 and 185 to save time, since it can take a while to read in all of the data.
#test <- links[184:185]
episodes <- lapply(links, function(x) read_csv(x, locale = locale(encoding = "ISO-8859-1")))
Now get the data into tidy format. This might not be the absolute best way of doing it, but it’s pretty easy and quick. First use map_df from purrr to bind all the list elements together in a dataframe. That gives me a very messy dataframe with one column for each episode.
episodes <- episodes %>%
map_df(bind_cols, .id = "source")
So I can just use gather to put them in the proper (long) format that I want, and filter out the NAs resulting from the different columns.
episodes <- episodes %>%
gather(title, text, -source) %>%
filter(!is.na(text))
Now I want to do some more text manipulation and cleaning. First I’ll look for speakers, which is usually a capitalized name followed by a colon. Then put the spoken text in a separate column. Note that there will be exceptions, text analysis is not an exact science and you can drive yourself crazy trying to fix small issues.
episodes <- episodes %>%
mutate(speaker = word(text, 1, sep = ":")) %>%
mutate(speaker = ifelse(speaker == text, NA, speaker)) %>%
mutate(line = word(text, 2, sep = ":"))
Now I’m basically going to filter out anything I’ve already determined is a scene description or other descriptive filler.
ep_text <- episodes %>%
filter(!is.na(speaker))
I’ll check to see how many lines each speaker has. This is also a good way to filter out descriptive text that wasn’t already filtered out in the previous step.
temp <- count(ep_text, speaker) %>% arrange(desc(n))
For example, I see that “CUT TO” has 297 lines and “( CUT TO” has 126 lines, so I obviously want to get rid of it because that’s not a real speaker. This is where X-Files knowledge comes in handy, because I already know that “X” and DEEP THROAT" are actual speakers. I’m also going to get rid of speakers that are just numbers (formatting issue, probably times). I can’t just exclude all of the speakers that include numbers, because there are some that are legitimate. For example, “Man 1”, and there is an entire episode that takes place in the past (in addition to other flashbacks), so you have things like “1939 Scully”. It’s a great episode so I definitely don’t want to miss that! For that reason I’ll also just keep a character vector of speakers to exclude in addition to the str_detect. Getting rid of anything with a bracket is also partciularly useful. Finally, I will filter out any speaker with only one line, because this will get rid of a lot of noise as well.
temp <- temp %>% filter(n == 1)
ep_text <- ep_text %>%
filter(!str_detect(speaker, "CUT|From|from|The|the|\\[|\\(|\\?"),
!speaker %in% c("9", "10", "11", "5","8", "6", "7",
"2", "4", "12", "#1", "1", "3", "#2"),
!speaker %in% temp$speaker)
There are a couple of other duplication issues I want to fix, for example “Cigarette-Smoking Man” vs. “Cigarette Smoking Man”. I also want to make sure all of Mulder and Scully’s speaker names are uniform because I’m definitely going to use them in the analysis.
ep_text <- ep_text %>%
mutate(speaker = ifelse(
speaker %in% c(
"1939 CIGARETTE SMOKING MAN",
"CIGARETTE SMOKING MAN",
"CIGARETTE-SMOKING MAN",
"CANCERMAN",
"CANCER MAN"
),
"CIGARETTE SMOKING MAN",
ifelse(
speaker %in% c(
"1989 MULDER",
"MULDER",
"MULDER AS MORRIS",
"MULDER ON ANSWERING MACHINE",
"MULDER ON RECORDER",
"MULDER ON RECORDING",
"MULDER VOICE OVER",
"MULDER'S VOICE",
"MULDER'S VOICE OVER",
"VERY OLD MULDER"
),
"MULDER",
ifelse(
speaker %in% c(
"DANA",
"1939 SCULLY",
"FLASHBACK SCULLY",
"SCULLY",
"SCULLY ON MACHINE",
"SCULLY ON TAPE",
"SCULLY VOICE OVER",
"SCULLY'S VOICE OVER"
),
"SCULLY",
speaker
)
)
)) %>%
mutate(speaker = ifelse(str_detect(speaker, "MANICURE"), "WELL-MANICURED MAN", speaker)) %>%
mutate(speaker = str_to_title(speaker))
Now I’ll join the table from the previous post, by episode number. I’m going to save this dataset for the next post.
ep_text <- ep_text %>%
rename("no_overall" = source,
"ep_title" = title) %>%
mutate(no_overall = as.numeric(no_overall)) %>%
left_join(table_df, by = "no_overall") %>%
mutate(speaker = str_to_title(speaker))
Plotting Number of Lines Per Character
I’m going to do the text analysis in the next post, because this file will take forever to run and if I need to make small adjustments it’s going to be very time consuming. However, this post wouldn’t be complete without a chart, would it?
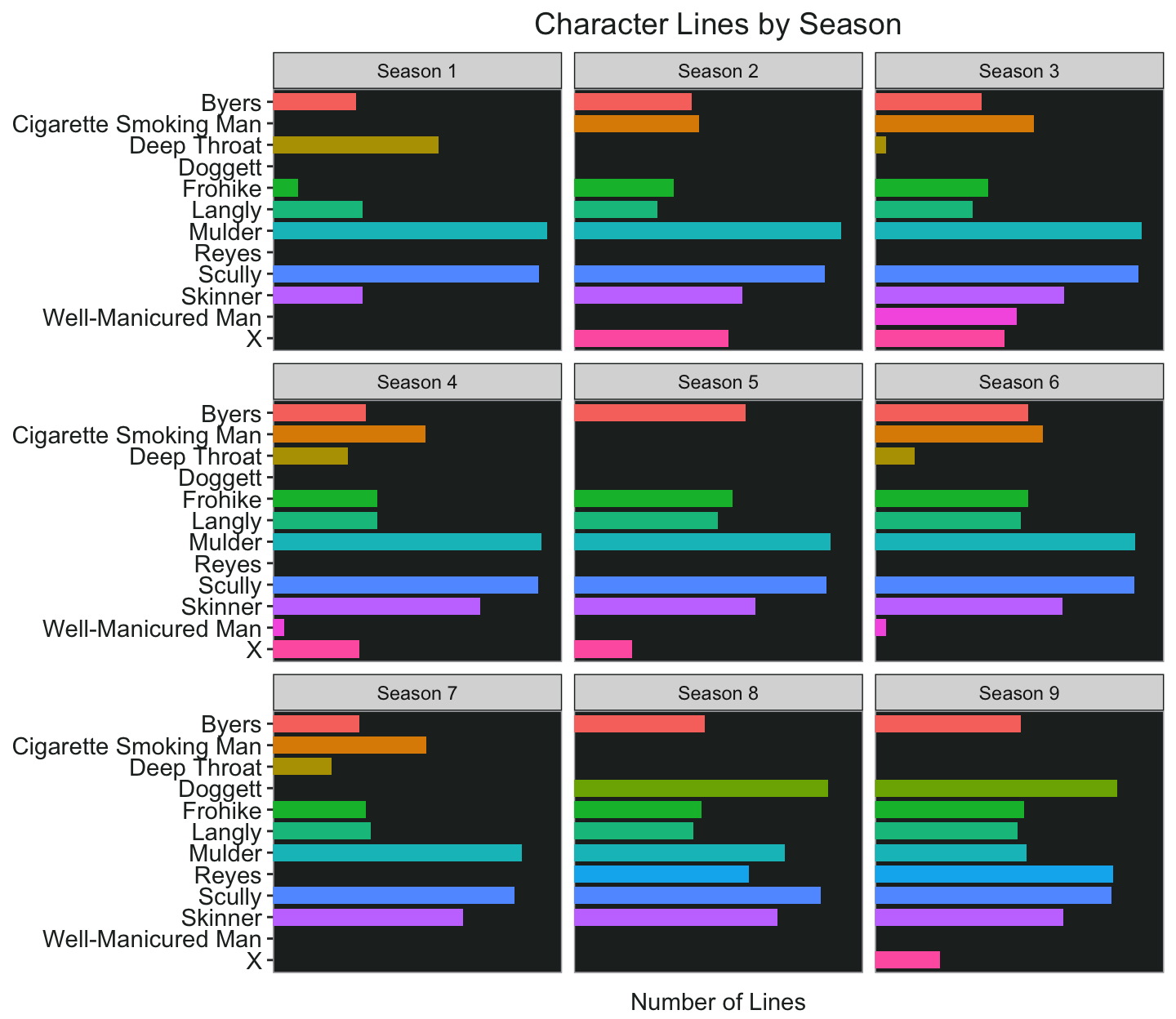
Let’s look at the number of lines each character has per season. Of course, for the sake of space I’m just going to pick some of the main characters. I will also change the number of lines into a log scale just to even things out for the chart, because Mulder and Scully have the highest number of lines by a long shot, so the secondary characters will be harder to see.
speakers <- ep_text %>%
count(season, speaker) %>%
filter(
speaker %in% c(
"Mulder",
"Scully",
"Skinner",
"Cigarette Smoking Man",
"Frohike",
"Langly",
"Doggett",
"Reyes",
"Byers",
"X",
"Deep Throat",
"Well-Manicured Man"
)
) %>%
arrange(season, desc(n))
speakers <- speakers %>%
mutate(n2 = round(log(n), 2),
speaker2 = factor(speaker)) %>%
mutate(n2 = ifelse(n2 < .5, .3, n2))
speakers %>%
ggplot(aes(fct_rev(speaker2), n2,fill =speaker2)) +
geom_col(show.legend = FALSE, width = .8, position = position_dodge(0.7))+
facet_wrap(~season, nrow = 3)+
scale_y_continuous(limits = c(0,8), expand = c(0,0))+
coord_flip()+
labs(title = "Character Lines by Season", y = "Number of Lines")+
my_theme2